Our journey with Flink: automation and deployment tips

Introduction
Apache Flink is a great framework for building data processing applications. In our team, we love it for the wide range of use cases it allows us to tackle, the simplicity to get started with it, its very comprehensive documentation, and the lively community evolving around it.
We have been developing with it for a few years now, to process the real time video quality data sent by Mesh Delivery and CDN Load Balancer end users, and today our Flink applications process thousands of messages every day along the road, and in this article, we will share a few key aspects of how we deploy and operate our Flink applications.
Split responsibilities: one Flink cluster = one Flink application
Flink applications run on Flink clusters. A cluster is a combination of one or several Job Managers and one or several Task Managers. Job Managers are the brains of the cluster: they receive requests for submitting applications to run on the cluster, and they schedule it on the Task Managers. Task Managers are the muscles of the cluster: they are the workers actually running the applications.
You can run as many Flink applications as you want on a single Flink cluster, provided that you have enough Task Managers on your cluster. But our experience showed us that it’s better to have as many Flink clusters as applications to run. This allowed us to:
- adapt the resources in each cluster to the needs of the application running on it
- isolate the applications from one another and avoid propagating errors / bugs in one job to other applications
Examples for this second point are situations where submitting an application to the Job Manager leads to the crash of the Job Manager process. If all your applications are running on the same cluster, they all rely on the same Job Manager so they will all be affected and stop unexpectedly (unless you use a Highly Available setup with Zookeeper for your Job Managers, which is not always possible).
Anticipate: make regular savepoints of your applications
One of the super cool Flink features is the checkpointing mechanism. Checkpoints are backups of the application state at a given point in time. In your application code, you can ask Flink to take regular checkpoints (it is recommended if your application has some kind of state that you don’t want to lose when the application stops).
| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Enables checkpoints env.enableCheckpointing(conf.getCheckpointsFreqMs()); env.getCheckpointConfig().setCheckpointTimeout(conf.getCheckpointsTimeoutMs ());env.getCheckpointConfig().setMaxConcurrentCheckpoints(conf.getMaxConcurrent Checkpoints()); env.getCheckpointConfig().setTolerableCheckpointFailureNumber(conf.getToler ableCheckpointFailures()); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(conf.getCheckpoints MinPauseTimeMs()); |
Checkpoints are great because you can restart the application from them if it unexpectedly failed. But there are some limitations, and in some situations, you might be unable to restart your application from a given checkpoint.
Flink has a more advanced type of checkpoint, called savepoints, that need to be triggered externally (i.e. cannot be triggered from the code). Restarting a job from a savepoint works almost all the time, so it’s better to have one to restart your job from, especially after an application crash that requires some non-trivial changes to be made on the application code. In that case (when the application schema changed), a savepoint is the only way to make sure that you are able to restart your job without losing the state of the application. So, to avoid finding ourselves forced to restart stateful applications from scratch (with empty states), we configured a simple cron job (to run every 15 minutes) on each of our Job Managers to make regular savepoints of our applications.
| echo “$(date)”
# Finds the id of the application
if [ -z “${JOB_ID}” ]; then
# Takes a savepoint of the job, and include the date in the path |
That way, we won’t have to restart an application with a state older than 15 minutes before a potential crash.
Automate: take advantage of the Flink API for CD
Another great thing about Flink clusters is that you can do a lot of things with the Flink API exposed by the Job Managers. You can use it to get the list of jobs running on the cluster, check the last checkpoints taken by a given job, take a savepoint of a running job, stop a running application, submit a new application to run on the cluster, etc. All of these steps are actually what you need to do when you need to update / redeploy a Flink application. So we bundled those API calls in simple Python scripts, and used those scripts to set up Continuous Deployment on our Flink applications.
For example, we have a script deploy_or_update_job.py, which goes to the Job Manager:
- stops the application if it’s running and takes a savepoint (/jobs/{job_id}/stop)
- uploads a given JAR to the Job Manager (/jars/upload)
- runs the JAR with specified command line parameters (using the last savepoint taken for that job) (/jar/{jar_id}/run)
Additionally, we created Docker images that allow us to use those scripts alongside the appropriate JAR files containing the Flink jobs to run. A sample of our CD process (with Google Cloud Build) looks like this:
| # Clone the data-flink-scripts repository – name: ‘gcr.io/cloud-builders/git’ entrypoint: ‘bash’ args: – -c – | eval “$(ssh-agent -s)” ssh-add /root/.ssh/id_rsa_data_flink_scripts git submodule update –init — data-flink-scripts volumes: – name: ‘ssh’ path: /root/.ssh –id: ‘build image’ name: ‘gcr.io/cloud-builders/docker’ args: [ ‘build’, ‘-t’, ‘my-flink-job’, ‘.’ ] – id: deploy name: ‘gcr.io/cloud-builders/docker’ entrypoint: ‘bash’ args: – -c – | docker run -e FLINK_JOBMANAGER_URL=http://10.x.x.x:8081 my-flink-job data-flink-scripts/deploy_or_update_job.py –job_name my-flink-job –parallelism 72 –-config_file my-conf-file.yaml |
Scale: leverage the Flink adaptive scheduler with Google Cloud Managed Instance Groups
Flink 1.13 came with a long-awaited capability: automatic rescaling of a Flink job. In this section, we will detail how we use the adaptive scheduler to automatically upscale / downscale our Flink application when the amount of data to process increases or decreases.
Flink allows you to choose between several types of strategies to decide how to use the slots available on a cluster (scheduler strategies). The scheduler that is useful for auto scaling is the adaptive scheduler, which uses all the slots available in a given cluster as long as the parallelism required when the application was launched is not reached). That scheduler will automatically restart your application if you add task managers to a cluster to use the new slots added by the new workers, and gracefully handle the loss of a worker by simply restarting the application with a lesser parallelism.
Step 1: create an instance template for the Task Managers
A Google Managed Instance Group is a set of identical machines performing a given task. When auto scaling is on, Google can automatically add new instances to the group based on an instance template.
In our case, we chose to base our instance templates on Google Container-Optimized OS, which are optimized for running Docker containers. We simply specify our custom Flink Task Manager Docker image (based on the official Flink Docker image) as the container to run when a new instance is spawned.
Step 2: create the instance group and configure the auto scaler
The setup that we have is:
- One VM running the Job Manager
- One Managed Instance Group where each worker runs a Task Manager
- Network connections allowed from the Job Manager to the Managed Instance Group
- Network connections allowed within the Managed Instance Group
We used the Instance Template created in Step 1 to create a Managed Instance Group, and we enabled the Google Auto Scaler on that Instance Group.
The Auto Scaler has four main parameters to fine tune:
- The minimum number of machines in the Instance Group
- The maximum number of Machines in the Instance Group
- The CPU utilization threshold (averaged across all instances) that the auto scaler will try to maintain (a good value for our Flink applications is 70%)
- The “cool down period,” which lets you adjust how much time it takes for one new instance to be fully working and prevents the auto scaler from making decisions too early after adding a new instance.
Step 3: correctly configure the Flink environment
There are a few things to adjust in the configuration if you want to use auto scaling for Flink applications.
In the Job Manager Flink environment
- Set the jobmanager scheduler to “adaptive”
- Set the “resource-wait-timeout,” the maximum time that the Job Manager will wait for at least one worker to be available to schedule your application (in case the Instance Group finds itself with zero workers for some reason)
- Adjust the heartbeat timeout duration: you want your job to react as quickly as possible to the deletion of a Task Manager (when your cluster is scaling down), so you need to change the value of `heartbeat.timeout` in the flink-conf.yaml. (for Job Manager AND Task Managers). A value of 15 seconds, for example, is large enough for us to avoid false positives, while allowing fast rescale of the application.
- Set a restart strategy in your application that sets no limit on the max number of restarts: each time a rescale event occurs, it is counted as a restart, so there should be no limit in the number of restarts the Job Manager can trigger before terminating the application. For our applications, we use the exponential Delay Restart strategy, but it’s also possible to stick with the fixed-delay restart strategy with Integer.MAX_VALUE restart attempts.
| jobmanager.scheduler: adaptive jobmanager.adaptive-scheduler.resource-wait-timeout: 3600 s hearbeat.timeout: 15000 restart-strategy.type: exponential-delay restart-strategy.exponential-delay.initial-backoff: 10 s restart-strategy.exponential-delay.max-backoff: 2 min restart-strategy.exponential-delay.backoff-multiplier: 2.0 restart-strategy.exponential-delay.reset-backoff-threshold: 10 min restart-strategy.exponential-delay.jitter-factor: 0.1 |
In the Task Manager Flink environment
- Set the heartbeat timeout.
- Set the number of task slots: Flink recommends you set one task slot per CPU available on your machine.
- Set the address of the Job Manager: all the Task Managers in your Instance Group should talk to the same Job Manager.
| jobmanager.rpc.address: x.x.x.x hearbeat.timeout: 15000 taskmanager.numberOfTaskSlots: 2 |
Step 4: deploy your applications and enjoy auto scaling!
The important thing to mention when deploying is that we set the parallelism of the job to a value higher than the total number of slots that we can have on the cluster. That way, the Job Manager starts the application using all the slots available.
When traffic increases, the Google Cloud auto scaler adds new Task Managers to the Managed Instance Group (when the Task Managers’ CPU utilization reaches the configured threshold). The Job Manager detects that there are new slots available, and since we configured an arbitrary high value for parallelism, it rescales the job to use all the new slots. When traffic decreases, Google autoscaler removes Task Managers (when CPU utilization is too low compared to the configured threshold). The Job Manager detects the loss of a Task Manager and simply restarts the job with a lower parallelism.
The graph below shows the typical shape of the number of Task Managers in one of our Flink cluster over time.
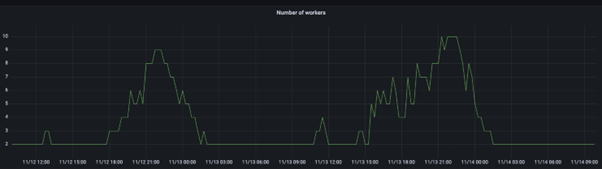
The auto scaling is not perfectly smooth; there is still some tuning to be done with the auto scaler settings, but overall we are quite happy with this setup as it allows us to save money without compromising on data quality, consistency and availability.
We hope that this article gave you some practical tips to operate and deploy your Flink applications! In our next article, we will show some development issues that we faced using Flink, and how we overcame them.
This content is provided for informational purposes only and may require additional research and substantiation by the end user. In addition, the information is provided “as is” without any warranty or condition of any kind, either express or implied. Use of this information is at the end user’s own risk. Lumen does not warrant that the information will meet the end user’s requirements or that the implementation or usage of this information will result in the desired outcome of the end user. All third-party company and product or service names referenced in this article are for identification purposes only and do not imply endorsement or affiliation with Lumen. This document represents Lumen products and offerings as of the date of issue.
Trending Now

How Huitt-Zollars built a future-ready digital foundation with Lumen




